
Manter a infraestrutura de TI de uma organização saudável, eficiente e segura é uma prioridade essencial para qualquer negócio que dependa de seus sistemas digitais. Nesse contexto, o monitoramento de servidores desempenha um papel fundamental como ferramenta de gestão e controle, possibilitando a supervisão contínua do desempenho, disponibilidade e segurança dos recursos de rede. Com o avanço das tecnologias de infraestrutura, incluindo ambientes físicos, virtuais e cloud, a complexidade do monitoramento também evoluiu, exigindo soluções cada vez mais sofisticadas e integradas.

O monitoramento de servidores consiste na aplicação de ferramentas e práticas que acompanham, em tempo real, diversas métricas relacionadas ao funcionamento de servidores físicos, virtuais ou hospedados em nuvem. Essas métricas incluem uso de CPU, memória, espaço em disco, tráfego de rede, tempo de resposta, disponibilidade de serviços e integridade geral do sistema. Através do acompanhamento contínuo dessas informações, gestores e profissionais de TI podem identificar precocemente sinais de falha, gargalos de desempenho ou riscos de segurança, adotando medidas preventivas ou corretivas de forma ágil e eficiente.
Um ponto central dessa prática é a coleta de dados, que pode ocorrer por meio de protocolos padrão como SNMP (Simple Network Management Protocol) e WMI (Windows Management Instrumentation), além de APIs específicas de plataformas de cloud e agentes instalados nos servidores. Essa captação de informações permite a construção de dashboards intuitivos, alertas automatizados e relatórios detalhados, essenciais para uma gestão proativa e orientada por dados.
Importância do monitoramento na estratégia de TI
Sem uma estratégia sólida de monitoramento, as empresas correm riscos significativos, incluindo aumento do tempo de inatividade, perdas de dados, vulnerabilidades de segurança e diminuição da satisfação dos usuários finais. A indisponibilidade de servidores críticos pode causar interrupções nos processos de negócios, afetando desde operações internas até a experiência do cliente.
Adicionalmente, o monitoramento eficaz contribui para o planejamento deCapacity Planning, permitindo que equipes de TI dimensionem recursos de forma adequada às demandas atuais e futuras. Isso evita o overprovisioning, que implica em desperdício de recursos, além do underprovisioning, que potencialmente causa falhas e lentidão.
Outro aspecto relevante é a segurança: ao monitorar atividades atípicas ou tentativas de intrusão, os sistemas podem disparar alertas preventivos, contribuindo para ações de defesa e redução de vulnerabilidades. Assim, o monitoramento se torna uma camada adicional de proteção, complementando outras iniciativas de segurança, como firewalls, antivírus e gestão de patches.
Benefícios do monitoramento de servidores
- Prevenção de falhas e downtime não planejado: A detecção precoce de problemas permite correções antes que afetem o funcionamento dos sistemas.
- Melhoria no desempenho operacional: Dados de uso das métricas ajudam a otimizar a alocação de recursos e ajustar configurações para maior eficiência.
- Redução de custos: Evitar interrupções inesperadas reduz perdas financeiras, além de possibilitar a escalabilidade inteligente de infraestrutura.
- Segurança aprimorada: Monitorar atividades suspeitas ou incomuns permite agir rapidamente para mitigar ameaças.
- Visibilidade e controle centralizado: Dashboards e relatórios consolidam informações, facilitando a tomada de decisão estratégica.
Para organizações que operam em ambientes híbridos — incluindo servidores on-premises, virtuais e na nuvem —, a integração de sistemas de monitoramento é ainda mais relevante, pois assegura uma visão holística e integrada do ecossistema de TI.
Ferramentas de monitoramento de servidores
No mercado, há diversas soluções, desde plataformas open source até softwares comerciais SaaS (Software as a Service), cada uma com suas vantagens e particularidades. Entre as opções de destaque encontram-se soluções como Zabbix, Nagios, PRTG Network Monitor, SolarWinds Server & Application Monitor, e plataformas completas como Site24x7, ManageEngine OpManager, entre outras.
Analizar as necessidades específicas do ambiente, o orçamento disponível e o nível de automação desejado são fatores que orientam a escolha da ferramenta apropriada. Empresas que buscam maior customização e integração podem optar por soluções open source, enquanto aquelas que preferem menor esforço de implementação e suporte técnico de fornecedores identificam-se com plataformas SaaS.
Importância de uma estratégia de implementação eficaz
Implementar o monitoramento de servidores não é apenas adquirir uma ferramenta, mas também definir processos, rotinas e políticas que garantam o melhor uso possível do sistema. Isso inclui a parametrização de métricas, configuração de alertas, instalação de agentes, integração com sistemas de automação e IA, além de treinamentos para equipes.
Por fim, a manutenção contínua, atualização de dashboards e revisão periódica das métricas monitoradas são práticas essenciais para que o monitoramento seja uma verdadeira alavanca para a performance, disponibilidade e segurança da infraestrutura de TI.
Conforme avançamos neste tema, entender os detalhes de cada passo da instalação, configuração e uso dessas ferramentas garante uma gestão de alta confiabilidade, permitindo às organizações garantir a continuidade dos seus serviços e agregar maior valor ao negócio.
Configuração avançada e estratégias para otimizar o monitoramento de servidores
Após entender os fundamentos e as vantagens do monitoramento de servidores, o próximo passo crucial para garantir uma infraestrutura robusta é a implementação de configurações avançadas e estratégias bem definidas. Essas ações visam não apenas detectar problemas de forma proativa, mas também otimizar o desempenho e a segurança dos ambientes de TI de forma contínua.
Um aspecto fundamental nessa etapa é a personalização de dashboards, que devem refletir as métricas mais relevantes para a operação específica de cada organização. Utilizar visualizações intuitivas ajuda na rápida identificação de anomalias, facilitando ações corretivas imediatas. Por exemplo, em ambientes que utilizam servidores virtuais, dashboards que consolidam o uso de CPU, memória e armazenamento de várias máquinas virtuais em uma única tela possibilitam uma gestão centralizada e eficiente.

Outro componente essencial para o sucesso do monitoramento é a definição de limites e thresholds precisos. Estabelecer limites realistas para métricas como uso de CPU ou tráfego de rede evita alertas falsos e garante que os incidentes sejam tratados de forma eficaz. Além disso, a automação de respostas — como reiniciar um serviço ou servidor ao detectar uma falha — minimiza o tempo de inatividade e reduz a necessidade de intervenção manual, acelerando a resolução de problemas.
Para isso, é fundamental que as equipes de TI adotem políticas de gestão de incidentes bem estruturadas, incluindo rotinas de revisão e ajustes contínuos de limites e alertas. A integração do sistema de monitoramento com plataformas de automação, como ferramentas de orquestração de TI ou scripts personalizados, amplia a capacidade de resposta rápida e eficaz.
Outro passo que pode elevar o nível de monitoramento é a implementação de inteligência artificial e machine learning. Essas tecnologias permitem a análise preditiva, que identifica padrões de comportamento antes que uma falha ocorra, possibilitando ações preventivas. Assim, uma organização que investe em soluções com esses recursos consegue antecipar problemas, otimizando custos e evitando impactos negativos na experiência do usuário final.
Além disso, estratégias de gestão de logs integrados ao sistema de monitoramento elevam o controle operacional. Centralizar logs de eventos, acessos, atividades suspeitas e falhas em uma única plataforma facilita a auditagem e a identificação de causas raiz de incidentes complexos. A utilização de soluções que enriquecem esses logs com metadados auxilia na rastreabilidade, fundamental para conformidade e segurança.
Por fim, a adoção de rotinas de revisão periódica de métricas, limites e configurações deve ser uma prática constante. O cenário de TI está em contínua evolução, com novas vulnerabilidades, atualizações de sistemas e mudanças de carga de trabalho. Manter o sistema de monitoramento atualizado e ajustado às condições reais do ambiente garante uma gestão preditiva e resiliente, capaz de suportar as demandas atuais e futuras.
Investir em treinamentos periódicos para as equipes de TI também é estratégia fundamental, garantindo que os profissionais saibam explorar ao máximo as funcionalidades das ferramentas e estejam preparados para lidar com incidentes complexos. Assim, a combinação de configuração inteligente, automação, análise preditiva e treinamento contínuo ajuda as organizações a manterem alta disponibilidade, segurança e desempenho de sua infraestrutura de TI.
Para empresas que buscam um suporte especializado, opções de consultoria e implementação de sistemas avançados de monitoramento oferecem valor agregado, assegurando que as estratégias adotadas estejam alinhadas às melhores práticas do mercado.
Configurações avançadas para fortalecer o monitoramento de servidores
Após compreender a importância fundamental do monitoramento de servidores e os componentes essenciais que devem ser acompanhados, um próximo passo vital é a implementação de configurações avançadas que potencializam a eficácia dessa prática. Essas configurações não só auxiliam na detecção proativa de problemas, mas também elevam a capacidade de resposta e a segurança da infraestrutura de TI. Para empresas que utilizam servidores de diferentes ambientes — sejam físicos, virtuais ou na nuvem —, a personalização do monitoramento por meio de dashboards intuitivos e alertas automáticos significa a diferença entre uma gestão reativa e uma abordagem verdadeiramente proativa.

Detalhes como a configuração de limites e thresholds de métricas, por exemplo, são essenciais para evitar alarmes falsos ou alertas insuficientes. Para isso, definir limites realistas, com bases em padrões históricos e capacidade operacional, garante que notificações sejam enviadas apenas quando realmente houver uma condição de risco. Assim, as equipes de TI podem concentrar esforços na resolução de incidentes relevantes, evitando interrupções desnecessárias.
A automação de respostas — uma estratégia que vem ganhando destaque — amplia ainda mais esses benefícios. Ferramentas de monitoramento modernas permitem configurar ações automáticas ao detectar uma anomalia, como reiniciar serviços, desligar ou reiniciar servidores, ou até mesmo redirecionar tarefas para sistemas de orquestração. Essa automação minimiza o tempo de inatividade e elimina a necessidade de intervenção manual imediata, fator crítico para ambientes com alta demanda de disponibilidade.
Para maximizar a precisão dessas ações, a integração de sistemas de inteligência artificial (IA) e machine learning (ML) oferece possibilidades avançadas de análise preditiva. Esses recursos analisam padrões de comportamento dos servidores ao longo do tempo e identificam sinais de inadimplência ou degradação antes que uma falha aconteça realmente, permitindo uma manutenção preditiva eficaz.
Além disso, a implementação de políticas de gerenciamento de logs, aliada a dashboards consolidando essas informações, proporciona uma visão holística de toda a operação. Logs de eventos, acessos e atividades suspeitas são enriquecidos com metadados, facilitando a rastreabilidade e a conformidade regulatória. Com uma rotina de revisão contínua dessas métricas, as organizações garantem uma postura de segurança reforçada e uma capacidade de resposta ágil a incidentes.
Outra configuração relevante é o ajuste dinâmico de thresholds com base em variáveis de carga, horários ou períodos de maior ou menor demanda. Essa estratégia evita alarmes desnecessários durante picos de uso ou baixas sazonais, focando apenas nas anomalias que realmente impactam a performance ou representam riscos de segurança.
Implementação de práticas de gestão baseadas em políticas
Para que as configurações avançadas de monitoramento realmente tragam benefícios sustentáveis, é imprescindível a adoção de políticas claras de gerenciamento de incidentes. Essas políticas devem definir rotinas de revisão de thresholds, processos de escalonamento, procedimentos de automação e treinamentos periódicos para as equipes de TI. Uma política bem estruturada garante que o monitoramento seja uma ferramenta de apoio, e não apenas uma tecnologia isolada, para uma gestão eficiente e segura.
Por exemplo, a política de automação deve estabelecer quais ações podem ser executadas automaticamente sem risco de causar impactos colaterais, além de definir limites de confiança nos sinais preditivos usados pelo sistema de IA. Da mesma forma, rotinas periódicas de auditoria e atualização de dashboards e métricas garantem que os sistemas estejam alinhados às atuais demandas do ambiente de TI, que está em constante evolução.
Treinamento e capacitação contínua
Para que as configurações avançadas atendam suas expectativas, é imprescindível investir na capacitação contínua das equipes de TI. Treinamentos específicos sobre as ferramentas de automação, análise preditiva, gerenciamento de logs e configuração de dashboards tornam-se diferenciais competitivos, permitindo uma exploração plena das funcionalidades disponíveis. Dessa forma, gestores e profissionais de TI transformam o monitoramento em uma prática estratégica de prevenção, performance e segurança.
Quanto maior a familiaridade das equipes com as configurações avançadas, mais eficaz será a sua implementação. Como consequência, as organizações terão uma infraestrutura mais resiliente, com menor risco de downtime, maior eficiência operacional e políticas de segurança reforçadas — elementos indispensáveis em um cenário de TI cada vez mais dinâmico e ameaças crescentes.

Para consolidar esse ciclo de melhorias, recomenda-se a realização de auditorias internas periódicas, revisão de políticas e simulações de incidentes. Assim, a organização assegura que suas configurações estejam alinhadas às melhores práticas do mercado, promovendo uma cultura de monitoramento proativo e de alta confiabilidade.
Implementar configurações avançadas de monitoramento de servidores não é apenas uma questão técnica, mas uma estratégia que exige planejamento, disciplina e inovação constante. Assim, as empresas podem alinhar suas operações de TI às exigências de disponibilidade, desempenho e segurança, entregando maior valor aos negócios e fortalecendo sua competitividade no mercado.
Configurações avançadas para fortalecer o monitoramento de servidores
Após compreender os fundamentos do monitoramento de servidores e suas vantagens, a implementação de configurações avançadas é crucial para ampliar a eficiência e a precisão dessa prática. Personalizar dashboards para refletir métricas específicas de cada ambiente permite uma visualização mais clara e rápida do estado da infraestrutura, facilitando a identificação de anomalias e coordenando ações corretivas de forma ágil.
Dashboards bem configurados são essenciais para uma gestão otimizada de servidores heterogêneos. Em ambientes com servidores virtuais ou hospedados em diferentes provedores cloud, consolidar informações em telas únicas fornece uma visão holística, reduzindo o tempo de resposta a incidentes e apoiando decisões estratégicas de expansão ou ajuste de recursos.
Outra configuração fundamental é a definição de limites ( thresholds) e alertas com base em métricas realistas. Estabelecer limites que considerem a capacidade operacional histórica e a carga atual evita notificação de falsos positivos ou alertas que possam passar despercebidos. Assim, o time de TI pode concentrar esforços apenas nas situações que realmente representam um risco à performance ou à segurança.
Automatizar respostas a incidentes, como reiniciar serviços ou reinicializar servidores, aprimora o tempo de reação e minimiza o impacto de falhas. Para isso, é necessário configurar políticas de automação que considerem diferentes níveis de criticidade, evitando ações desnecessárias ou que possam agravar o problema.

A implementação de inteligência artificial (IA) e machine learning (ML) é um passo estratégico para elevar o nível de monitoramento. Essas tecnologias possibilitam a análise preditiva, que identifica padrões de comportamento antes que uma falha aconteça, permitindo ações preventivas de manutenção e ajuste de recursos. Assim, é possível reduzir custos operacionais e evitar paradas não planejadas, garantindo maior estabilidade para o negócio.
Além disso, a gestão de logs centralizada reforça o controle operacional. Centralizar logs de eventos, acessos e atividades suspeitas garante rastreabilidade e facilita auditorias de conformidade. A análise enriquecida desses registros fornece insights valiosos para identificar vulnerabilidades e otimizar políticas de segurança.
Outro aspecto importante é o ajuste dinâmico de thresholds, que considera variáveis como horários de pico ou sazonalidades. Essa prática evita alarmes falsos durante períodos de alta demanda e mantém o foco apenas em atividades que realmente impactam a performance ou representam ameaças à segurança.
Implementação de políticas de gerenciamento baseadas em boas práticas
Para que as configurações avançadas de monitoramento tragam resultados sustentáveis, a adoção de políticas de gerenciamento bem estruturadas é imprescindível. Essas políticas devem definir rotinas de revisão periódica das métricas, limites e thresholds, garantindo que o sistema esteja sempre alinhado às mudanças do ambiente de TI.
Estabelecer processos de escalonamento para incidentes, bem como rotinas de auditoria em logs e dashboards, reforça a postura de segurança e confiabilidade da infraestrutura. Além disso, criar rotinas de treinamentos constantes para as equipes assegura que todos estejam capacitados a explorar ao máximo as funcionalidades das ferramentas de monitoramento, além de compreenderem os procedimentos de resposta automatizada.
Treinamento e capacitação contínua das equipes
Investir na formação contínua dos profissionais de TI é um diferencial que potencializa o sucesso de qualquer estratégia de monitoramento avançado. Treinamentos especializados em automação, análise preditiva, gerenciamento de logs e configuração de dashboards garantem a exploração pleno das funcionalidades e agilizam a resolução de problemas complexos.
Dessa forma, as equipes tornam-se mais autônomas e preparadas para ajustar as configurações conforme novas vulnerabilidades, atualizações de sistemas ou modificações na carga de trabalho. O resultado é uma infraestrutura de alta resiliência, com menor risco de downtime, maior performance operacional e políticas de segurança reforçadas.
Para consolidar estas boas práticas, recomenda-se realizar auditorias internas periódicas, revisões de políticas e simulações de incidentes. Essas ações preservam a efetividade das configurações, asseguram conformidade às normas regulatórias e fortalecem a cultura de monitoramento proativo.
Implementar configurações avançadas de monitoramento de servidores exige planejamento constante, disciplina na execução e uma cultura de inovação. Com esses elementos alinhados, as organizações transformam suas operações de TI em verdadeiros ativos estratégicos, capazes de sustentar crescimento, melhorar a segurança e garantir a continuidade dos serviços, mesmo nas condições mais desafiadoras.
Implementações de monitoramento avançado para servidores
Compreender as métricas básicas é fundamental, mas a implementação de configurações avançadas amplia o controle sobre a infraestrutura de TI. Uma estratégia eficiente envolve a personalização de dashboards detalhados, que centralizam as informações mais relevantes para cada ambiente de servidor, seja físico, virtual ou em nuvem. Essa personalização permite uma visualização intuitiva do desempenho, facilitando a identificação rápida de gargalos e vulnerabilidades.
Ao configurar dashboards, deve-se priorizar métricas específicas de cada contexto, como uso de CPU, memória, I/O de disco e tráfego de rede. Em ambientes híbridos, dashboards consolidam dados de diferentes plataformas, promovendo uma visão holística que otimiza a tomada de decisão e agiliza ações corretivas. Além disso, dashboards interativos permitem filtros por períodos, servidores ou protocolos, oferecendo uma análise aprofundada sob diferentes perspectivas.

Outro aspecto crucial na implementação dessas configurações é a definição de limites (thresholds) precisos e realistas. Estabelecer limites baseados em dados históricos e capacidades atuais evita alarmes falsos, mantendo as equipes focadas em incidentes realmente relevantes. A automação de respostas a esses limites — como reiniciar serviços ou disparar ações corretivas automáticas — eleva a eficiência operacional, reduzindo o tempo de inatividade e otimizando recursos humanos.
Para aumentar ainda mais o nível de automação e proatividade, a incorporação de tecnologias de inteligência artificial (IA) e machine learning (ML) permite a análise preditiva. Essas soluções identificam padrões e sinais precoces de degradação do sistema, possibilitando intervenções preventivas antes que problemas se agravem. Assim, os gestores de TI podem atuar de forma planejada, priorizando ações estratégicas de longo prazo.
Automatização de scripts e resposta a incidentes
Complementando a configuração de limites e dashboards personalizados, a automação de ações é uma grande aliada na gestão de servidores. Scripts automatizados podem reiniciar serviços, redirecionar cargas de trabalho ou aplicar patches, tudo configurado previamente para responder a condições específicas, sem intervenção manual. Essa estratégia garante uma resposta rápida e consistente a eventos que possamimpactar a performance ou a segurança do ambiente.
Por exemplo, ao detectar uma sobrecarga de CPU, um script pode automaticamente escalar recursos em ambientes cloud, ou reiniciar um serviço com alta utilização, minimizando riscos de downtime. Esta automação deve estar alinhada às políticas de gerenciamento de incidentes, garantindo que cada ação seja registrada, auditada e executada com limites de confiança estabelecidos, evitando ações desnecessárias ou prejudiciais.
Para potencializar ainda mais a eficiência, a integração de plataformas de IA e ML com sistemas de gerenciamento de eventos (SIEM) permite que a análise preditiva seja alimentada por grandes volumes de logs e eventos históricos. Com isso, é possível identificar padrões recorrentes e antecipar falhas com maior precisão, além de otimizar recursos de segurança e manutenção preventiva. Essas ações preditivas elevam a confiabilidade da infraestrutura, garantindo maior disponibilidade e segurança operacional.
Estratégias de gestão de logs integrados
A centralização de logs é uma prática indispensável na gestão moderna de servidores. Consolidar logs de eventos, acessos e atividades suspeitas em uma única plataforma permite uma análise de causa raiz mais rápida e precisa, além de facilitar auditorias de conformidade. Tecnologias que enriquecem logs com metadados e timestamps, facilitando a correlação de eventos, fortalecem a rastreabilidade e a transparência na gestão de segurança.
Para isso, deve-se definir rotinas de revisão periódica, que envolvam análise de logs históricos, identificação de padrões anômalos e atualização contínua de políticas de acesso. Essas práticas garantem a detecção precoce de ameaças e evitam que incidentes se tornem crises de segurança, além de propiciarem a conformidade com normas regulatórias como a LGPD.
Graduação das thresholds e estratégias dinâmicas
O ajuste dinâmico de thresholds, considerando variáveis sazonais ou de carga, protege o ambiente contra alarmes falsos. Durante períodos de pico, limites podem ser aumentados automaticamente, enquanto em horários de menor uso, limites mais restritivos ajudam a identificar anomalias reais. Essa estratégia não apenas evita alertas desnecessários, mas também permite ações automatizadas de escalabilidade e balanceamento de carga, essenciais para ambientes de alta disponibilidade.
Ferramentas de automação, combinadas com algoritmos de IA, possibilitam definir limites adaptativos, que evoluem conforme o comportamento do sistema. Essas soluções minimizam o esforço de manutenção e garantem uma resposta eficiente às variações naturais de demanda, protegendo recursos e melhorando a experiência do usuário final.
Boas práticas na implementação de políticas de monitoramento
Implementar políticas bem estruturadas de gerenciamento de incidentes e automações exige planejamento rigoroso. Cada rotina deve estabelecer critérios claros de ativação, níveis de criticidade, responsáveis e cronogramas de revisão. Ademais, treinamentos constantes para as equipes asseguram o entendimento dos procedimentos e a rápida adaptação a mudanças tecnológicas e de ambiente.
Revisões periódicas, auditorias internas e simulações de incidentes são essenciais para garantir a efetividade das políticas. Essas práticas mantêm as equipes preparadas e o sistema de monitoramento alinhado às melhores práticas de mercado, elevando a resiliência operacional e a segurança da infraestrutura.
Capacitação contínua das equipes de TI
Investir na formação contínua é chave para o sucesso de estratégias avançadas de monitoramento. Treinamentos especializados em automação, análise preditiva, gerenciamento de logs e automação de respostas tornam-se diferenciais competitivos. Além de explorar as ferramentas disponíveis, as equipes devem aprender a interpretar dados complexos e ajustar estratégias com base em insights gerados por IA e ML.
Essa capacitação propicia maior autonomia, agilidade na resolução de incidentes e maior alinhamento às tendências de mercado, principalmente em ambientes híbridos. Profissionais bem treinados são capazes de elaborar políticas adaptativas, implementar automações inteligentes e conduzir análises preventivas, fortalecendo a segurança e a disponibilidade do ambiente.

Participar de workshops, treinamentos práticos e atualizações regulares garante que as organizações estejam alinhadas às boas práticas emergentes, além de promover uma cultura de inovação e prevenção contínua. Dessa forma, a infraestrutura de TI se torna uma vantagem competitiva, capaz de suportar o crescimento do negócio e mitigar riscos de alta complexidade.
Integração de tecnologias como inteligência artificial e machine learning para monitoramento preditivo de servidores
Na busca por maximizar a confiabilidade e antecipar falhas, a incorporação de inteligência artificial (IA) e machine learning (ML) nas estratégias de monitoramento de servidores tem se destacado como uma tendência essencial. Essas tecnologias possibilitam a análise de grandes volumes de dados históricos e em tempo real, identificando padrões e sinais de degradação antes que problemas se tornem críticos. Assim, equipes de TI podem agir de forma preventiva, reduzindo o tempo de inatividade e evitando impactos severos ao negócio.
Por exemplo, algoritmos de ML podem aprender o comportamento típico de uso de recursos, ajustando thresholds automaticamente conforme variam as cargas de trabalho. Essa adaptação dinâmica evita alarmes falsos e garante que alertas sejam gerados apenas em situações reais de risco, otimizando a eficiência operacional. Além disso, sistemas de IA podem sugerir ações corretivas automáticas, como redistribuição de cargas ou reinicializações inteligentes, aumentando a agilidade na resposta a incidentes.
Ferramentas de monitoramento de última geração integram esses recursos de IA/ML em dashboards intuitivos, capazes de fornecer insights preditivos e oferecer recomendações de otimização. Ao combinar análise preditiva com automação, sua infraestrutura de TI torna-se mais resiliente, capaz de manter alta disponibilidade mesmo diante de cargas variáveis ou ameaças avançadas.
Gestão avançada de logs integrada ao monitoramento de servidores
Centralizar logs de eventos, acessos, atividades suspeitas e falhas em uma plataforma única representa uma estratégia que reforça o controle operacional e a conformidade regulatória. A gestão eficiente de logs, aliada às boas práticas de enriquecimento de metadados e timestamps, facilita a correlação de eventos e a identificação de causas raiz de incidentes complexos. Assim, a organização consegue atuar de forma mais rápida e precisa na resolução de problemas, além de garantir maior rastreabilidade para auditorias e conformidades, como LGPD.
Implementar rotinas de revisão contínua dessas informações, com análises preditivas baseadas em IA, permite ajustar políticas de segurança e de resposta a incidentes de forma antecipada. Logs enriquecidos com metadados auxiliam na detecção de atividades atípicas, invasões ou tentativas de manipulação, fortalecendo os mecanismos de defesa da infraestrutura.
Além disso, a integração de logs ao sistema de monitoramento propicia uma visão holística do ambiente, facilitando o gerenciamento de eventos em ambientes híbridos, que combinam servidores on-premises, virtuais e cloud. Com essa estratégia, a organização mantém uma postura proativa na mitigação de vulnerabilidades e na manutenção da alta disponibilidade, tudo isso por meio de uma gestão baseada em dados confiáveis e de fácil acesso.

Implementação de políticas dinâmicas de thresholds e automação inteligente
Para garantir uma resposta eficaz às variações operacionais, estabelecer limites (thresholds) dinâmicos, ajustados automaticamente com base em variáveis de carga, horários e sazonalidades, é uma prática avançada que minimiza alarmes falsos e concentra a atenção nos incidentes que realmente impactam o sistema. Essa personalização aprimora a relevância das notificações e evita intervenções desnecessárias que podem gerar indisponibilidade ou desperdício de recursos.
Complementarmente, a automação de ações corretivas, como reiniciar servidores, ajustar recursos de cloud ou redirecionar cargas de trabalho, permite uma resposta ágil e consistente, mesmo em ambientes com alta criticidade. Essas respostas automáticas, alimentadas por algoritmos de IA, elevam o nível de proatividade, reduzindo significativamente o tempo de inatividade e otimizando a operação.
Políticas bem estruturadas de gerenciamento de incidentes, com rotinas de escalonamento e revisão periódica dessas thresholds e automações, formam o alicerce de uma infraestrutura resiliente. Resultado: uma gestão que evolui continuamente em alinhamento às mudanças do ambiente de TI, sempre garantindo alta disponibilidade e segurança operacional.
Capacitação contínua das equipes de TI para suportar estratégias avançadas
O sucesso na implementação de configurações avançadas de monitoramento depende, substancialmente, do treinamento e da capacitação contínua das equipes de TI. Profissionais treinados não apenas operam de modo mais eficiente as ferramentas de automação, IA, gerenciamento de logs e dashboards, mas também são capazes de interpretar dados complexos, ajustar thresholds e responder de forma autônoma a ameaças emergentes.
Investir em treinamentos especializados, workshops, simulações de incidentes e atualizações frequentes funde-se à cultura de melhoria contínua, que se reflete na maior resiliência e agilidade da infraestrutura. Equipes bem preparadas evitam erros operacionais, potencializam o uso das funcionalidades integradas e mantêm um ambiente em conformidade com as melhores práticas do mercado.
Essa capacitação deve estar alinhada a uma rotina de auditorias internas, revisões de políticas e avaliações de desempenho. Assim, a organização transforma sua força de trabalho em um ativo estratégico, capaz de antecipar problemas, responder com agilidade e sustentar níveis elevados de disponibilidade e segurança.

Considerações finais
A combinação de monitoramento inteligente, gestão integrada de logs, políticas dinâmicas de thresholds, automação e capacitação constante forma o alicerce de uma infraestrutura de TI altamente confiável. Empresas que adotam essas estratégias antecipam-se às falhas, reduzem custos com incidentes não planejados e fortalecem sua postura de segurança, permitindo a continuidade operacional mesmo em cenários de alta complexidade.
Investir em tecnologias de IA e ML, aliado a uma cultura de melhorias contínuas, garante que sua organização esteja sempre à frente na jornada de excelência operacional, elevando seus padrões de disponibilidade, desempenho e segurança no gerenciamento de servidores.
Ferramentas de automação e integração para monitoramento eficiente de servidores
Na busca por uma gestão de TI cada vez mais otimizada, a automação de tarefas repetitivas e a integração de diferentes sistemas de monitoramento tornam-se essenciais. Utilizar scripts automatizados, integrados com plataformas de IA, permite que equipes de TI reduzam o tempo de resposta a incidentes, além de minimizar erros humanos. Por exemplo, automatizar a reinicialização de serviços, ajustes dinâmicos de thresholds ou a implantação de patches incrementa a resiliência da infraestrutura e garante operações ininterruptas.
Ferramentas modernas de monitoramento oferecem APIs abertas e compatibilidade com plataformas de automação, facilitando a criação de workflows customizados. Essa integração possibilita ações coordenadas, como o redirecionamento automático de cargas de trabalho durante picos, aplicação de patches em horários de menor impacto, e envio de alertas preditivos com recomendações específicas, tudo em uma única plataforma consolidada, como o valuehost.com.br.
Outro aspecto que potencializa o monitoramento de servidores é a utilização de redes de sensores e agentes que coletam métricas de múltiplos pontos do ambiente, enviando para um centro de processamento inteligente. Essa arquitetura distribuída melhora a granularidade das análises, permitindo detectar anomalias com alta precisão antes mesmo que resultem em falhas.
Gestão de incidentes com políticas baseadas em melhores práticas
Estabelecer políticas claras de gestão de incidentes é fundamental para o sucesso de qualquer sistema de monitoramento avançado. Essas políticas devem contemplar rotinas de revisão de thresholds, procedimentos de escalonamento e ações automáticas de resposta predefinidas. A definição desses fatores deve ser baseada em análises de risco, histórico de incidentes e capacidades de resposta do time.
Implementar sistemas de tickets integrados ao monitoramento garante uma rastreabilidade eficiente das ações corretivas, além de facilitar a análise de causas e a prevenção de incidentes recorrentes. Tudo isso deve estar alinhado a uma estratégia de treinamento contínuo das equipes de TI, que precisa ser alimentada por cursos especializados e workshops de atualização, promovendo uma cultura de alta confiabilidade e proatividade.

Para garantir a efetividade dessas políticas, recomenda-se revisar regularmente as métricas, limites e estratégias de automação, utilizando dashboards dinâmicos que representam o estado atual do ambiente. A adoção de sistemas de inteligência artificial permite ajustar thresholds de forma automática, de acordo com variações sazonais ou de carga, evitando falsos positivos e alarmes falsos.
Treinamento e capacitação contínua para equipes de monitoramento
O sucesso na aplicação de estratégias de monitoramento de alta performance está diretamente ligado à capacitação constante das equipes de TI. Investir em treinamentos específicos sobre uso de plataformas de automação, análise preditiva, gerenciamento de logs, e interpretação de dashboards com IA garante maior autonomia, rapidez na tomada de decisão e uma postura mais proativa na manutenção da infraestrutura.
Adicionalmente, a realização de simulações de incidentes, auditorias de processos e revisões periódicas de políticas de monitoramento reforçam práticas de alta confiabilidade. Essa cultura de melhoria contínua resulta em uma infraestrutura de servidores mais resiliente, com menor risco de downtime, maior eficiência operacional e uma postura de segurança reforçada, alinhada às melhores práticas do mercado.
Portanto, a combinação de ferramentas de automação inteligentes, políticas de gestão estruturadas, integração de sistemas e capacitação constante forma a espinha dorsal de uma estratégia moderna de monitoramento de servidores. Essa abordagem não só reduz custos operacionais, como também aumenta a disponibilidade, otimiza o desempenho e garante maior segurança, fatores que elevam a competitividade e a capacidade de resposta de sua organização.
Procedimentos essenciais para a implementação eficaz do monitoramento de servidores
Após compreender a importância de um monitoramento aprofundado e segmentado, a etapa seguinte envolve a implantação de procedimentos estruturados que garantam a eficiência, escalabilidade e segurança dessa prática. Uma implementação bem-sucedida depende de uma abordagem estratégica, alinhada às necessidades específicas do ambiente de TI da organização, e que considere fatores como infraestrutura, políticas internas e visão de longo prazo.
Um ponto central nesta fase é a definição clara das políticas de monitoramento, que envolvem a padronização de métricas a serem observadas, níveis e thresholds de alerta, rotinas de resposta automática e processos de escalonamento de incidentes. Essas políticas devem ser revisadas periodicamente para adaptarem-se às mudanças no ambiente operacional, mudanças tecnológicas e evoluções nas ameaças de segurança.
Para garantir uma implementação consistente, é fundamental estabelecer uma equipe responsável pela configuração, operação e revisão contínua do sistema de monitoramento. Essa equipe deve ser treinada regularmente, não apenas para operação das ferramentas, mas também para interpretação dos dados, identificação de padrões anômalos e acionamento de procedimentos de correção. A capacitação contínua, aliada à documentação detalhada de processos e políticas, é uma estratégia que reduz riscos operacionais e garante respostas ágeis e padronizadas.
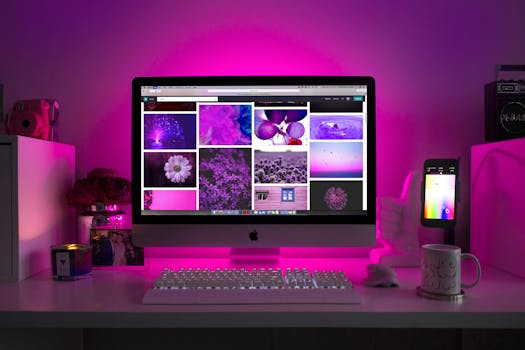
Outro procedimento essencial é a automação de tarefas repetitivas por meio de scripts e rotinas automatizadas. Como mencionado em tópicos anteriores, a automação reduz o tempo de resposta, elimina possibilidades de erro humano e aumenta a eficiência operacional. A integração com plataformas de inteligência artificial e machine learning, quando possível, permite a implementação de respostas preditivas, que antecipam falhas com base em análises de tendências e padrões históricos.
A definição de uma frequência de revisão das configurações do sistema também é crucial. Rotinas de auditoria mensais, trimestrais ou semestrais devem ser estabelecidas para verificar a pertinência das métricas monitoradas, validade dos thresholds e aderência às políticas de gerenciamento de incidentes. Além disso, a realização de testes periódicos de resposta a incidentes e simulações de falhas ajudam a identificar possíveis gargalos na cadeia de comando, permitindo ajustes antes que uma crise real ocorra.
Documentação e padronização de processos de monitoramento
Para garantir a continuidade e escalabilidade do monitoramento, a documentação completa de todos os procedimentos, configurações, scripts, dashboards e políticas é indispensável. Essa documentação deve estar disponível para toda a equipe envolvida e deve ser atualizada conforme alterações nas ferramentas ou estratégias.
Padronizar a implementação dos processos assegura uma uniformidade na atuação, facilitando treinamentos, auditorias internas e transferências de conhecimento. Além disso, essa prática melhora a rastreabilidade dos incidentes e facilita a análise de causas raízes, promovendo melhorias contínuas na infraestrutura de TI.
É aconselhável estabelecer uma rotina de relatórios periódicos que consolidem métricas de desempenho, incidentes ocorridos, ações corretivas e melhorias implementadas. Esses relatórios auxiliam a avaliação do desempenho do sistema de monitoramento, identificam pontos frágeis e demonstram a evolução da infraestrutura ao longo do tempo, contribuindo para o alinhamento estratégico da TI com os objetivos de negócio.
Integração de sistemas de monitoramento com outros processos de TI
A integração das ferramentas de monitoramento aos processos maiores de gestão de TI, como incident management, mudança, configuração e continuidade de negócios, potencializa a eficiência e a capacidade de resposta. Sistemas de gerenciamento de eventos, plataformas de automação e centros de operações de segurança (SOC) devem estar conectados às soluções de monitoramento, formando uma arquitetura integrada que possibilita respostas automatizadas, correlação de eventos e análises preditivas.
Por exemplo, a integração com sistemas de gestão de tickets automatiza a abertura e acompanhamento de incidentes, enquanto a correlação de logs e eventos auxilia na identificação de ameaças de segurança, reduzindo o tempo de resposta a vulnerabilidades e minimizando riscos de attack surfaces expostos.
A adoção de APIs abertas e protocolos padronizados, como REST ou SOAP, permite maior flexibilidade na integração de diferentes sistemas e facilita futuras expansões e atualizações na infraestrutura de monitoramento. Assim, a organização garante uma base sólida para o crescimento, além de assegurar uma resposta coordenada entre equipes técnicas, de operações e de segurança.
Monitoramento contínuo: chave para alta disponibilidade e segurança
A implementação de procedimentos robustos não termina na instalação inicial. O monitoramento de servidores deve seguir uma cultura de melhoria contínua, com revisões periódicas, ajustes de thresholds, atualizações de dashboards e treinamentos de equipes. Essa postura proativa maximiza a disponibilidade, reduz riscos de falhas não detectadas e fortalece a segurança do ambiente de TI, que deve responder às ameaças em evolução com agilidade e precisão.
Bons procedimentos de monitoramento, aliados a uma equipe bem treinada e processos documentados, tornam-se uma barreira eficaz contra incidentes, além de uma ferramenta de suporte estratégico que impulsiona a inovação e a competitividade da organização no mercado digital.
Integração de ferramentas de monitoramento com sistemas de automação e gestão de TI
Para potencializar a eficiência e a capacidade de resposta do monitoramento de servidores, a integração com plataformas de automação e gestão de operações de TI (ITSM) se torna imprescindível. Essa integração permite a criação de fluxos de trabalho coordenados, onde alertas geram ações automáticas, como reinicializações programadas, redirecionamento de tráfego ou escalonamento de incidentes para equipes específicas, de forma rápida e organizada. Assim, ao combinar dados de performance com processos automatizados, empresas podem reduzir drasticamente o tempo de inatividade e prevenir falhas recorrentes.
Ferramentas modernas de gestão de TI, como plataformas de orquestração e automação, dispõem de APIs abertas e compatibilidade com protocolos padrão (como REST e SOAP), facilitando a conexão com sistemas de monitoramento. Essa conectividade cria uma arquitetura de TI mais coesa e inteligente, onde eventos são correlacionados automaticamente, possibilitando uma análise preditiva e ações preventivas, além de garantir maior conformidade e controle centralizado de toda infraestrutura.
Por exemplo, uma plataforma de gerenciamento pode receber alertas de sobrecarga em recursos de um servidor específico, disparar automaticamente scripts de escalabilidade na nuvem, abrir tickets de incidentes, além de notificar equipes técnicas, tudo sem intervenção manual. Essa abordagem integra não só o monitoramento, mas também o ciclo completo de manutenção, automação, segurança e conformidade, aprimorando a resiliência da infraestrutura como um todo. A utilização de APIs abertas também promove a flexibilidade na expansão de soluções futuras, compatibilidade com novos protocolos e facilidade de atualização, garantindo uma estratégia de longo prazo alinhada às necessidades de negócio.
Gerenciamento avançado de logs como suporte à segurança e análise de incidentes
A centralização e o gerenciamento inteligente de logs de eventos, acessos e atividades suspeitas é fundamental para uma postura de segurança proativa e um ambiente de TI auditável. Sistemas modernos de monitoramento integram recursos de logs que garantem a coleta, o enriquecimento com metadados e a correlação automática de eventos, facilitando a identificação de padrões anômalos ou atividades potencialmente criminosas antes que resultem em incidentes críticos.
Implementar rotinas de análise preditiva de logs, por meio de tecnologias de IA, aumenta a capacidade de detectar ameaças sofisticadas, vulnerabilidades e tentativas de invasões. Essa análise contínua possibilita o ajuste dinâmico de políticas de acesso e segurança, além de suportar o compliance com normas como LGPD, ISO 27001 e demais regulamentações. Logs enriquecidos com timestamps e metadados também simplificam auditorias, elucidação de causas-raiz e ações corretivas rápidas.
Mais do que isso, a integração de gestão de logs com ferramentas de automação permite a execução de ações corretivas automáticas, como bloquear acessos suspeitos, ajustar configurações de firewall ou disparar respostas em políticas de Zero Trust. Assim, a infraestrutura se torna mais resistente a ameaças internas e externas, enquanto mantém os processos de segurança atualizados frente às evoluções do cenário de ameaças cibernéticas.

Práticas recomendadas para a implementação e manutenção de sistemas de monitoramento avançados
Para garantir a efetividade sustentável do monitoramento de servidores, as empresas precisam estabelecer processos rotineiros de revisão, ajustes e atualização das políticas de monitoramento. Essas práticas envolvem revisões periódicas de thresholds, métricas e dashboards, considerando as cargas de trabalho reais, novas vulnerabilidades e mudanças no ambiente de TI. A automação de respostas, em conformidade com as políticas de segurança, deve ser revisada e calibrada continuamente para evitar falsos positivos e ações prejudiciais.
Além disso, a implementação de treinamentos constantes para as equipes de TI é essencial. Profissionais capacitados conseguem explorar ao máximo as funcionalidades dos sistemas, interpretar dados complexos e ajustar estratégias de forma autônoma. Treinamentos em técnicas avançadas de análise preditiva, automação baseada em IA, gerenciamento de logs e respostas automatizadas elevam o padrão de resiliência operacional.
Documentações detalhadas, procedimentos padronizados, rotinas de auditoria e relatórios de performance garantem a continuidade do ciclo de melhoria, facilitando transferências de conhecimento, escalabilidade e conformidade regulatória. Auditar e simular incidentes periodicamente, além de revisar as políticas de gerenciamento de incidentes, elevam a maturidade do sistema de monitoramento, prevenindo crises e fortalecendo a segurança geral.
Conclusão
Implementar e manter um sistema de monitoramento de servidores robusto, integrado às plataformas de automação, gestão de logs e inteligência artificial, constitui o alicerce de uma infraestrutura de alta disponibilidade, segurança e desempenho. Quanto mais estruturadas e treinadas as equipes estiverem, mais ágil será a identificação e resolução de incidentes, impulsionando a confiabilidade operacional.
Ao incorporar boas práticas de gestão, automação inteligente, análise preditiva e documentação rigorosa, as organizações não apenas previnem falhas e reduzem custos operacionais, mas também fortalecem sua resiliência frente às ameaças e incertezas do cenário tecnológico. Assim, o monitoramento de servidores deixa de ser uma atividade reativa e passa a atuar como uma estratégia proativa, gerando valor contínuo ao negócio, apoiando a inovação e garantindo vantagem competitiva no mercado digital.
O futuro do monitoramento de servidores aponta para a integração de tecnologias de ponta, como inteligência artificial e automação inteligente, que transformam a gestão tradicional em uma prática mais proativa e preditiva. Essas inovações visam reduzir drasticamente o risco de incidentes e otimizar recursos, garantindo níveis elevados de disponibilidade e segurança. Empresas que adotam essas estratégias se destacam ao oferecer ambientes de TI resilientes, capazes de antever problemas antes que eles afetem a operação.
Uma tendência forte é a implementação de plataformas que utilizam algoritmos de machine learning para análise preditiva, capazes de identificar padrões de degradação de desempenho ou sinais precoces de vulnerabilidade. Essa abordagem permite às equipes de TI agir preventivamente, realizando manutenções planejadas ou ajustando recursos de forma automatizada. Assim, a infraestrutura se torna não apenas mais inteligente, mas também mais flexível e responsiva às mudanças no ambiente de negócio.
Outro aspecto que promete revolucionar as práticas de monitoramento é a automação completa de respostas a incidentes. Sistemas avançados podem disparar ações corretivas sem intervenção humana, como reiniciar servidores, escalar recursos em nuvem, aplicar patches ou bloquear atividades suspeitas. Essa automação minimiza o tempo de inatividade e potencializa a segurança operacional, além de liberar recursos humanos para atividades estratégicas de maior valor agregado.
Não menos importante, a convergência de monitoramento com gestão de segurança cibernética (Security Information and Event Management – SIEM) permite uma abordagem integrada, onde a detecção de ameaças, o gerenciamento de logs e a resposta a incidentes operam de maneira coordenada. A combinação de dados de desempenho e logs de segurança, enriquecida por IA, potencializa a capacidade de identificar ameaças sofisticadas que podem passar despercebidas por sistemas convencionais.
Além disso, a implementação de dashboards dinâmicos, que se ajustam em tempo real às variáveis do ambiente, será fundamental para manter a equipe de TI atualizada e pronta para responder a qualquer cenário. Esses dashboards, alimentados por IA, podem fornecer recomendações instantâneas e automáticas de ações, otimizando a eficiência operacional.
Investir na capacitação contínua das equipes de TI também será um fator determinante. O desenvolvimento de competências em automação, análise preditiva, gerenciamento de logs e inteligência artificial garante que a organização possa explorar plenamente as vantagens dessas tecnologias avançadas. Com profissionais treinados, o monitoramento evolui de um processo reativo para uma estratégia de gestão preditiva, colocando a empresa um passo à frente das ameaças e problemas operacionais.
Por fim, a consolidação de um gerenciamento de riscos mais preciso, aliado à implementação de políticas de automação e revisão contínua das estratégias de monitoramento, proporcionará uma infraestrutura de TI extremamente robusta. Essa mudança de paradigma garante não só a alta disponibilidade de serviços, mas também a segurança e eficiência necessárias para competir em ambientes cada vez mais dinâmicos e ameaçados por vulnerabilidades emergentes.


